<tbody id="p8hbx"></tbody>
如若轉載,請注明出處:http://www.citymix.cn/product/18.html
更新時間:2026-03-15 09:23:50
成都小程序開發公司怎么樣如何判斷?
上新,檔次搞上去適合中介門店洽談桌更多產品vx搜小程序'
小程序零成本推廣:從0到100萬用戶的推廣套路
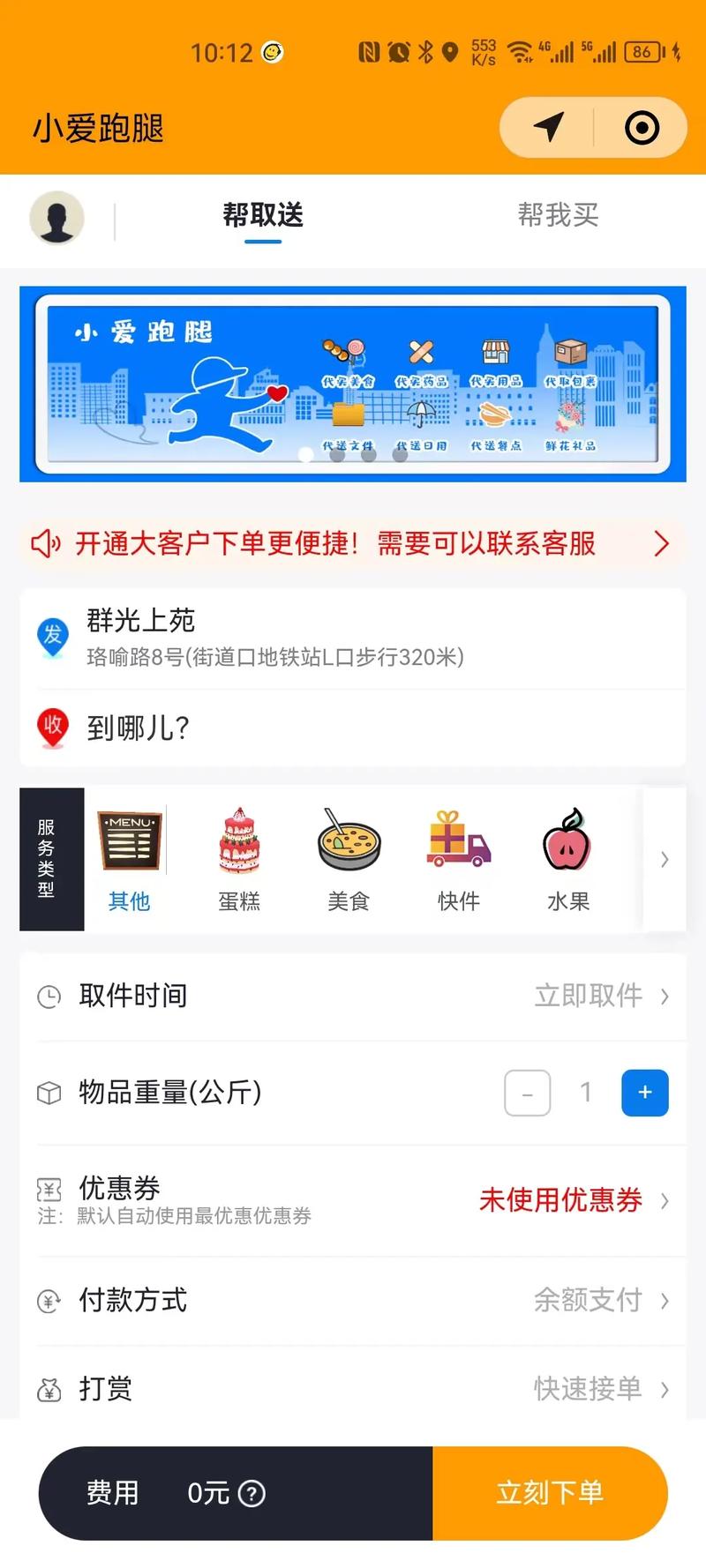
充電柜小程序開發的商業價值,服務人群定位
通知:微信5月19日后不再提供小程序打開App技術服務
武漢小程序開發公司.1.商城小程序是一個非常普遍的小程序類型
微信小程序 一
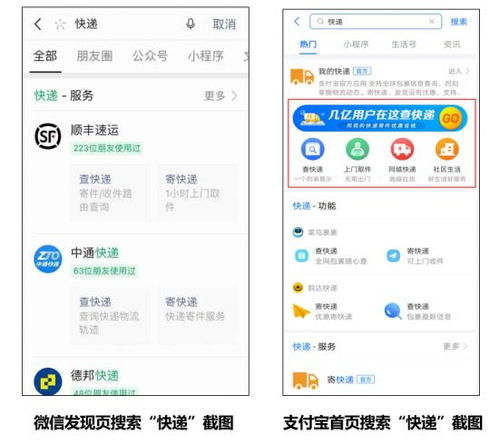
支付寶 微信 重兵 搜索,小程序下半場或 變天
如何從零開始開發微信小程序
python是人工智能的入門編程語言
電話:18078557025
地址:貴港市港北區北苑街280號(正佳電子城)617號
Copyright © 2026 www.citymix.cn 小程序 廣西貴港市新聯網絡科技有限公司 小程序 版權所有 Sitemap