如若轉載,請注明出處:http://www.citymix.cn/product/13.html
更新時間:2026-03-15 14:52:16
萬億級市場的車聯網,是真的新藍海,還是虛幻的蜃樓
恒記匠心農坊生鮮盒子--開在社區里的“菜籃子”
幫助中小商戶
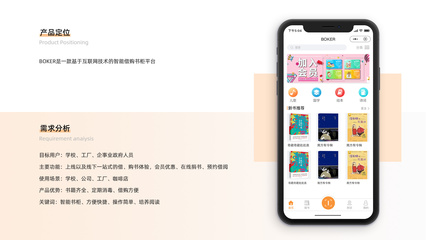
BOKER小程序
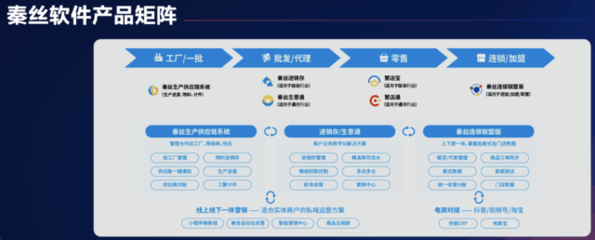
微信小程序 軟件平臺 商洛小程序開發本地
傳統電子商務平臺商家紛繁小程序店鋪怎樣分享到伴侶圈轉戰小程序,這是為什么?
家居團購網站獲IDG數千萬元戰投;社交電子商務小程序獲天使輪融資 小程序幾錢一個| 投資速遞
小程序流量紅利迸發,點幫熱鏈應用平臺告訴你哪些企業能搶到這波福利?
微信小程序的優勢,及適用行業
供應外賣小程序 專業小程序 云南東祝科技
電話:18078557025
地址:貴港市港北區北苑街280號(正佳電子城)617號
Copyright © 2026 www.citymix.cn 小程序 廣西貴港市新聯網絡科技有限公司 小程序 版權所有 Sitemap
<menuitem id="ryhdm"><delect id="ryhdm"></delect></menuitem>